한글 in NLP
NLP 시리즈
NLP는 어떤 것인가?
NLP_1 자연어 처리
NLP_2 자연어 처리-챗봇
NLP_3 NLP에서 영어와 한글의 차이
NLP_4 영어 in NLP
NLP_5 한글 in NLP
한글 in NLP
이번에는 한글의 경우 어떤 과정이 이루어지는지 간단한 예시 코드와 함께 알아보겠습니다.
전처리 과정과 챗봇에서 사용하는 작업(후처리)을 가지고 설명해 보았습니다.
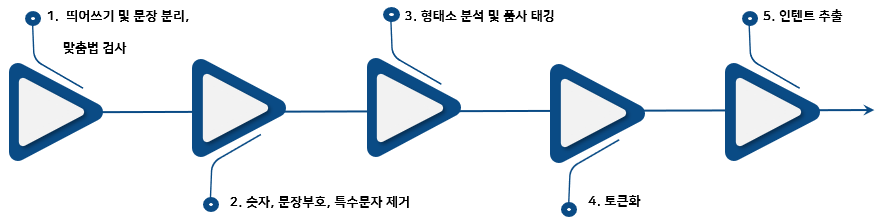
띄어쓰기 및 문장 분리, 맞춤법 검사
띄어쓰기 및 문장 분리는 마침표나 공백(띄어쓰기)를 기준으로 분리할수 있습니다.
한글은 띄어쓰기나 문장 분리가 제대로 지켜지지 않아도 의미 전달에는 큰 문제가 없기 때문에, 영어의 대소문자 처리 과정처럼 필수는 아닙니다. 하지만 모델의 성능에 영향을 줄 수 있어 전처리 과정에서 고려해야 할 사항입니다.
맞춤법 검사는 문법이나 띄어쓰기의 오류를 검출하여 올바르게 변환하는 작업입니다.

띄어쓰기와 맞춤법 검사 둘 다 라이브러리를 제공하며, 맞춤법 검사기를 이용해 띄어쓰기도 수정 가능하기 때문에 한 번에 오류를 해결할 수 있습니다.
맞춤법 검사기 라이브러리로 띄어쓰기와 맞춤법 오류를 수정하는 파이썬 코드는 다음과 같습니다.
코드 결과는 주석 처리하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
# 네이버 맞춤법 검사기인 py-hanspell 불러오기
from hanspell import spell_checker
sent1 = '나랑쇼핑하러갈래?외식도 하면 좋을것 같아.'
check_sent1 = spell_checker.check(sent1)
print(check_sent1.checked)
#나랑 쇼핑하러 갈래? 외식도 하면 좋을 것 같아.
sent2 = '맞춤법 틀리면 외 않되. 그냥 쓰면 돼는거아닌가'
check_sent2 = spell_checker.check(sent2)
print(check_sent2.checked)
#맞춤법 틀리면 왜 안돼. 그냥 쓰면 되는 거 아닌가
숫자, 문장부호, 특수문자 제거
영어와 마찬가지로 데이터와 개발 목적에 따라 필요시 이루어집니다. 모델의 성능에 영향을 주기 때문에 상황을 잘 고려하여야 하며, 특수 문자는 특수한 경우를 제외하고는 보통 제거하는 것이 좋습니다.
정규표현식을 이용하여 특수 문자를 제거하는 파이썬 코드는 다음과 같습니다.
정규표현식에 대한 내용은 추후 업데이트 할 예정입니다.
코드 결과는 주석 처리하였습니다.
1
2
3
4
5
6
7
8
import re
sent = '오늘 하늘은 정말 맑아! :)'
#정규표현식으로 특수 문자 제거하기
rm_char_sent = re.sub(r'[^가-힣\s]', '', sent) #한글과 공백만 남기기
print(rm_char_sent)
#오늘 하늘은 정말 맑아
형태소 분석 및 품사 태깅
한글은 교착어이기 때문에 형태소 분석이 중요합니다. 형태소들이 결합하여 단어를 이루며, 어떻게 결합하느냐에 따라 다양한 의미를 가집니다. 여러 조합으로 기존의 단어를 변형해 새로운 단어를 만들 수 있기 때문에 형태소 분석을 통해 단어의 의미 파악이 쉬워집니다.
또 복잡한 문법 구조를 가진 한글 문장에서의 문법적 관계를 이해하고 처리할 수 있습니다. 이는 문장을 분석하고 키워드를 추출하는데 유용하게 사용되어 검색, 번역, 요약 등 NLP의 여러 작업에 반영됩니다.
한국어 형태소 분석은 KoNLPy를 사용하며, Hannanum, Kkma, Komoran, Mecab, Okt로 5가지 분석기가 포함되어 있습니다.
Kkma(꼬꼬마)는 분석 퀄리티가 좋지만 느린 속도로 대용량이나 실시간 처리에 적용하기가 어렵습니다. Okt는 소셜 분석을 대상으로 하여 비형식 언어나 신조어를 잘 찾고, 처리 속도가 빠르나 품질은 떨어지는 결과를 보입니다. Mecab-ko는 분석에 필요한 시간도 가장 낮고 문자 수가 증가해도 안정적이며 좋은 분석 능력을 가집니다. 하지만 윈도우에서는 지원되지 않아 쉽게 접근하기 어렵습니다. KOMORAN은 자소 분리나 오탈자에 대한 성능이 좋지만, 자소 분리는 너무 자세하게 분석되는 경향이 있어 고려해보아야 합니다.
각 형태소 분석기에 대한 설명과 비교, 코드는 형태소 분석기 글에 정리하였습니다.
품사 태깅은 형태소 분석기를 사용하여 형태소나 명사를 추출하는데, 명사 추출이 일반적으로 사용됩니다.
Okt 형태소 분석기를 이용해 형태소를 분석하고 품사를 태깅하는 파이썬 코드는 다음과 같습니다.
코드 결과는 주석 처리하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from konlpy.tag import Okt
# Okt 형태소 분석기 불러오기
okt = Okt()
sent = '나랑 쇼핑하자.'
morphs = okt.morphs(sent)
pos = okt.pos(sent)
nouns = okt.nouns(sent)
print("형태소 분석:", morphs)
print("품사 태깅:", pos)
print("명사 추출:", nouns)
#형태소 분석: ['나', '랑', '쇼핑', '하자', '.']
#품사 태깅: [('나', 'Noun'), ('랑', 'Josa'), ('쇼핑', 'Noun'), ('하자', 'Verb'), ('.', 'Punctuation')]
#명사 추출: ['나', '쇼핑']
토큰화
한글 토큰화 방법은 자음과 모음, 음절, 형태소, 하위단어, 형태소 기반 하위단어, 단어 단위의 총 6가지 방법이 있습니다. Word는 영어처럼 단어 단위로 분할한 것이고, CV는 자음과 모음을 모두 분할, 음절은 음절 수준으로 한글자씩 분할, 형태소는 형태소 분석기 기준으로 분할, 하위단어 vocabulary라는 단어 사전에 있는 가장 작은 단어로 분할, 형태소 인식 하위단어는 형태소 분석기로 분류한 뒤 하위단어로 토큰화 한 것입니다.
영어의 기본 토큰화 방식인 단어 단위 토큰화는 음절의 의미를 파악하지 못하며, 형태소 분석도 되지 않아 단어가 문장에서 가지는 관계성을 알 수 없습니다. 반면에 형태소 기반 Subword 단위는 단어와 하위 단어를 이용해 정확하게 단어를 표현할 수 있습니다. 또 형태소 분석을 통해 명사와 동사 등을 구분하여 토큰화합니다.
그래서 현재 한글의 토큰화 기법에서는 하위단어, 형태소 기반 하위단어 토큰화 방법이 다양한 task에서 좋은 성능을 보입니다.
토큰화에 대한 설명과 방법마다의 결과 코드는 추후 업데이트 할 예정입니다.
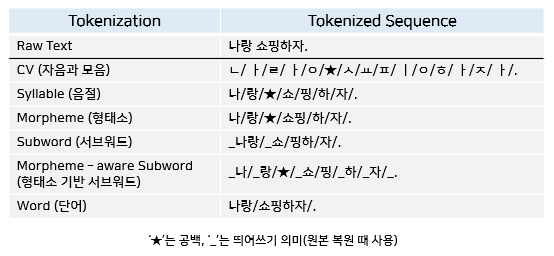 토큰 단위마다 다른 토큰화 결과
토큰 단위마다 다른 토큰화 결과
각 단위마다의 토큰화 결과는 An Empirical Study of Tokenization Strategies for Various Korean NLP Tasks 논문을 참고하였습니다.
BERT 토크나이저를 이용해 문장을 토큰화하는 파이썬 코드는 다음과 같습니다.
코드 결과는 주석 처리하였습니다.
1
2
3
4
5
6
7
8
from transformers import BertTokenizer
# BERT 토크나이저 불러오기
tokenizer = BertTokenizer.from_pretrained("bert-base-multilingual-cased")
tok = tokenizer.tokenize('나랑 쇼핑하자.')
print(tok)
#['나랑', '쇼핑', '##하', '##자', '.']
인텐트 추출
문장에서 인텐트를 추출하여 챗봇이나 AI 상담, 질의 응답 등에 사용합니다. 사용자 말의 의도를 파악하고, 이 인텐트를 기준으로 대화나 답변을 처리합니다.
예를 들어, 예약이 가능한지 질문하는 여러 방법의 문장에서 ‘예약’이라는 인텐트를 추출하여 사용자가 원하는 것이 무엇인지 알아냅니다.
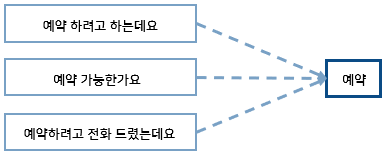 인텐트: 예약의 가능 여부
인텐트: 예약의 가능 여부
Comments powered by Disqus.