자연어 처리
NLP 시리즈
NLP는 어떤 것인가?
NLP_1 자연어 처리
NLP_2 자연어 처리-챗봇
NLP_3 NLP에서 영어와 한글의 차이
NLP_4 영어 in NLP
NLP_5 한글 in NLP
자연어 처리
자연어 처리는 Natural Language Processing으로 NLP라고 불립니다.
컴퓨터가 자연어를 이해, 생성, 조작할 수 있도록 하는 AI의 한 분야로, 자연어 데이터는 텍스트나 음성으로부터 얻을 수 있습니다.
자연어는 사람들이 일상적으로 쓰는 언어를 말합니다.
NLP는 텍스트나 음성 데이터의 구조와 의미를 파악한 후 데이터를 처리하고 해석합니다.
구조화되지 않은 텍스트 기반 데이터로부터 유용한 정보를 얻기 위해서도 사용합니다.
기계 번역, 문서 요약, 감성 분석, Siri와 같은 개인 비서 서비스 등에 적용되어 사용되고 있습니다.
NLP는 자연어 이해(NLU)와 자연어 생성(NLG)으로 나눌 수 있습니다.
- 자연어 이해(Natural Language Understanding)는 컴퓨터가 자연어를 이해할 수 있도록 하는 것에 초점을 둡니다.
글의 문맥, 의도, 정서뿐만 아니라 언어의 뉘앙스까지도 이해할 수 있도록 하는 것이 목표입니다. - 자연어 생성(Natural Language G)은 데이터 기반 또는 규칙을 통해 자연어를 만들어내는 것에 초점을 둡니다.
따라서 사람(사용자)이 쉽게 이해할 수 있는 텍스트를 만들어, 사람의 언어로 소통 가능하게 만드는 것이 목표입니다.
NLU와 NLG는 이해와 생성이라는 면에서는 차이를 가지지만, 사람과 컴퓨터가 문장을 사용해서 상호 작용하며 소통하는 점은 같습니다.
자연어 처리 흐름
NLP는 크게 데이터 수집, 데이터 전처리, 모델 구축 순으로 이루어집니다.
1. 데이터 수집
데이터는 모델의 성능(결과)에 아주 중요한 영향을 미치는 요소입니다.
그렇기 때문에 모델 학습에 알맞은지, 학습에 충분한 양을 가지고 있는지, 질이 좋은 데이터인지 유의하여 수집합니다.
AI Hub, 공공 데이터 포털, Kaggle 등에서 원하는 데이터를 얻을 수 있습니다.
2. 데이터 전처리
수집한 데이터는 모델 학습 전 NLP 알고리즘이 텍스트를 제대로 분석할 수 있게 정제, 가공 과정을 거칩니다.
특수문자 제거, 오타 교정이나 토큰화, 품사 태깅 등이 전처리 과정에 속해 있습니다.
3. 모델 구축
원하는 작업(task)에 맞게 NLP 알고리즘을 개발하고, 이를 전처리된 데이터에 적용하여 모델을 구축합니다.
데이터 분석 -> 학습 데이터 수집 및 추가 -> 모델 학습 -> 모델 평가 사이클을 돌며 모델의 성능을 개선합니다.
일반적으로는 감성 분석, 텍스트 분류, 기계 번역 등의 작업이 있으며, 모델로는 BERT, GPT 등이 있습니다.
자연어 처리 적용
자연어 처리는 의료, 법률, 금융과 같은 특수 분야뿐만 아니라 언어가 사용되는 분야라면 거의 모두 적용되기 때문에 대부분의 사람들이 접해본 경험이 있을 것입니다.
다양한 분야에서 많이 사용하고 있는 챗봇이 가장 큰 예입니다.
챗봇은 사람이 하는 여러 반복 작업을 대신 처리해 줍니다.
다량의 문의 글이나 전화를 예전에는 사람들이 일일히 대응하여 처리하였다면, 요즘은 대부분 챗봇 시스템을 사용해 처리를 합니다.
다양한 사용자의 요청을 데이터베이스의 적절한 항목과 매칭하여, 사용자에게 필요한 올바른 정보를 제공합니다.
챗봇에 대해서는 자연어 처리-챗봇에서 좀 더 자세하게 포스팅하였습니다.
챗봇 외에는 대규모의 문서를 분석하거나 정리할 때, 사람들이 원하는 것을 쉽게 파악하고 시장의 반응을 통계로 확인하는 시장 분석 및 마케팅 등에 적용하여 쓰입니다.
자연어 처리 과정
자연어 처리 과정을 순차적으로 자세하게 보면, 다음 그림과 같습니다.
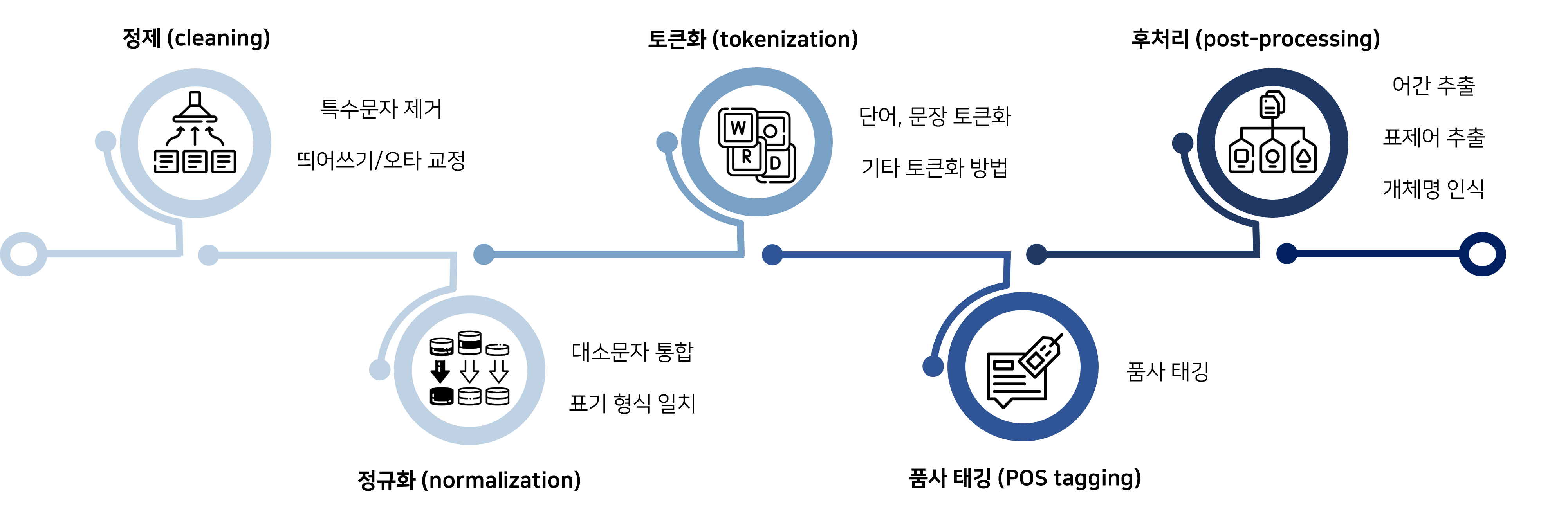
1. 정제 (cleaning)
데이터 전처리에서의 정제는 분석 결과에 불필요한 요소들을 제거 및 수정하는 과정입니다.
정제가 제대로 되지 않은 데이터들은 모델 학습에 노이즈를 발생하며, 성능에 악영향을 미칩니다.
정제 과정에는 특수문자 제거, 오타 교정 등이 있습니다.
2. 정규화 (normalization)
정규화는 데이터 간의 표현 방법을 통합시키는 과정으로, 일관성을 가지게 만들어줍니다.
영어 텍스트 데이터에서 대소문자를 통합하는 것, 줄임말이나 약자를 규칙성 없이 사용했을 때 표기 형식을 일치시키는 것 등이 정규화 과정에서 이루어집니다.
3. 토큰화 (tokenization)
토큰화는 텍스트를 개별 단위(구두점, 공백 등)로 분할하는 것입니다.
단어 토큰화, 문장 토큰화 등이 있습니다.
토큰화(tokenization)에서 토큰화에 대해 포스팅하였습니다.
4. 품사 태깅 (POS tagging)
품사 태깅은 문장 내의 단어에 해당하는 각 품사를 태깅하는 것입니다.
품사는 한 단어가 어떤 역할을 하는지 또는 무슨 의미를 갖는지 부여해서 구분해주는 것입니다.
Part of Speech의 줄임말로 POS라 하며, 품사 태깅을 pos 태깅이라고도 부릅니다.
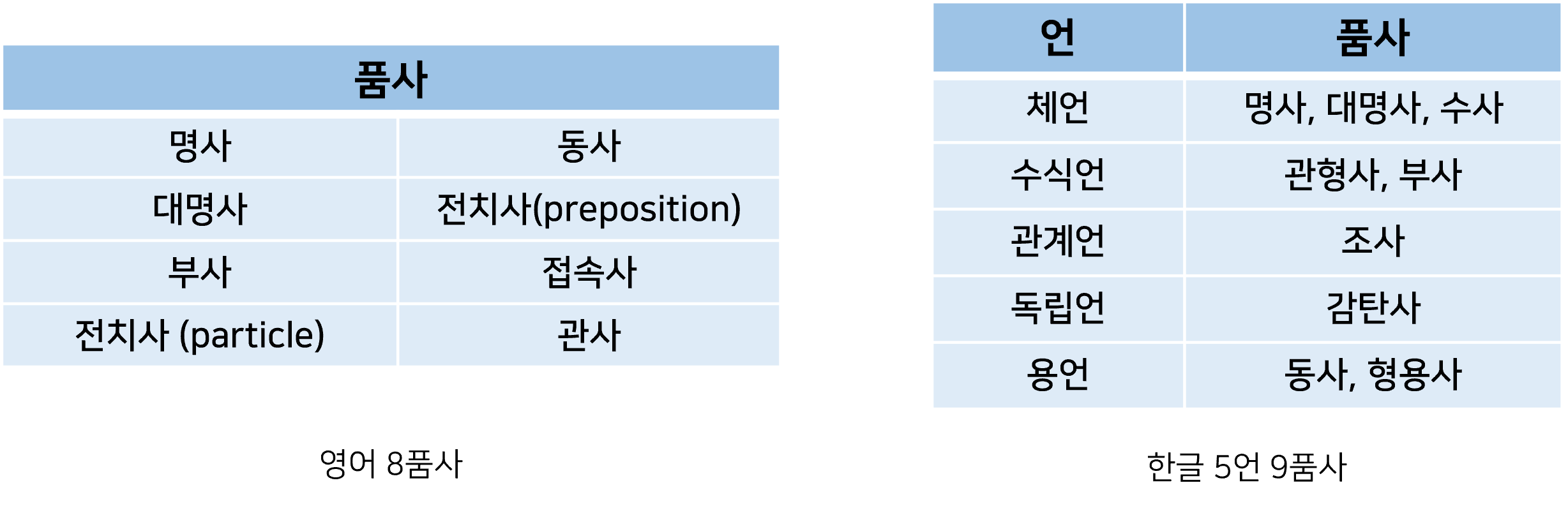
영어는 8가지의 품사를 가지고, 한글은 5언 9품사를 가집니다.
5. 후처리 (post-processing)
후처리는 전처리 과정 후의 작업들을 말합니다.
불용어(stopwords) 제거, 어간(stem) 추출, 표제어 추출, 개체명 인식 등이 있습니다.
불용어 제거는
I, you, he, 나는과 같이 텍스트 데이터에 자주 등장하지만 특별한 의미가 없는 단어들을 불용어라 지정하여, 분석에서 제외시키기 위해 제거하는 것을 말합니다.의미를 제공하는 기본 단어인 어간을 추출하여 단어가 갖는 의미를 추출하는 것을 어간 추출이라 합니다.
하지만 형태학적 분석을 단순화한 것으로, 어미를 자른 단어를 모델이 이해하기 어렵기 때문에 어간 추출로 단어를 분석하기에는 부족함이 있습니다.표제어 추출은 서로 다른 단어 형태를 가지지만, 파생되기 전 기본형을 찾아 하나의 단어로 취급하는 것을 말합니다. 예로,
am, is, are은be에서 파생된 단어이므로 모두be로 분류합니다.개체명 인식은 텍스트에서 단어가 어떤 의미를 뜻하는지 찾는 것으로,
비 오는 날에는 칼국수가 먹고싶어에서비(날씨),칼국수(음식)으로 개체명을 인식할 수 있습니다.
일반적인 NLP 과정을 보여주는 것이며, 원하는 task에 맞는 과정들을 선택하여 개발합니다.
Comments powered by Disqus.