영어 in NLP
NLP 시리즈
NLP는 어떤 것인가?
NLP_1 자연어 처리
NLP_2 자연어 처리-챗봇
NLP_3 NLP에서 영어와 한글의 차이
NLP_4 영어 in NLP
NLP_5 한글 in NLP
영어 in NLP
앞의 포스팅에서 ‘자연어 처리에서 영어와 한글의 차이’에 대해 글을 썼습니다.
그렇다면 NLP에서 영어는 어떤 과정을 거치는지 간단한 예시 코드와 함께 알아보겠습니다.
전처리 과정과 챗봇에서 사용하는 작업(후처리)을 가지고 설명해 보았습니다.
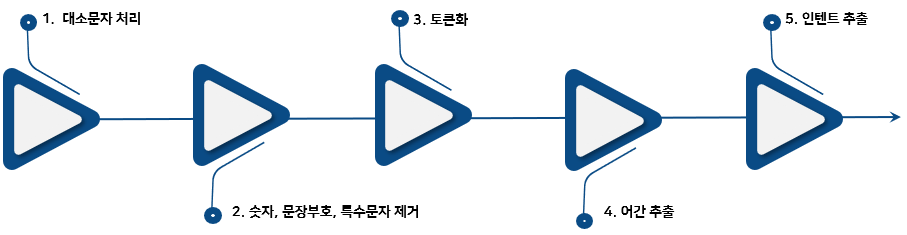
대소문자 처리
대소문자 처리 과정은 필수는 아니지만, 이를 구분해야하는 경우와 구분하지 않아도 되는 경우로 나눌 수 있습니다.
주소나 지명, 이름과 같은 고유명사와 축약어 등을 인식해야하는 경우에는 대소문자를 구분해줘야 합니다.
하지만 문장을 이해하는데에 있어 큰 영향을 주지는 않아, 보통 소문자로 통일하여 사용합니다.
소문자를 대문자로, 대문자를 소문자로 변형하는 파이썬 코드는 다음과 같습니다.
코드 결과는 주석 처리하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#소문자를 대문자로 변형하기
ori = 'Happy Birthday'
trans_u = ori.upper()
print('original sentence:', ori)
print('transformed sentence:', trans_u)
#original sentence: Happy Birthday
#modified sentence: HAPPY BIRTHDAY
#대문자를 소문자로 변형하기
trans_l = ori.lower()
print('original sentence:', ori)
print('transformed sentence:', trans_l)
#original sentence: Happy Birthday
#transformed sentence: happy birthday
#문장에 소문자가 있는지 확인하기(True, False)
trans_u.isupper()
#True
trans_u.islower() #대문자로 변형한 문장이므로 소문자 없음
#False
trans_l.isupper() #소문자로 변형한 문장이므로 대문자 없음
#False
trans_l.islower()
#True
숫자, 문장부호, 특수문자 제거
다음은 전처리의 기본인 특수 문자에 대한 처리입니다.
숫자와 문장 부호, 특수 문자 또한 필요한 경우와 필요하지 않은 경우가 있기 때문에, 데이터와 개발 목적에 따라 필요시 이루어집니다.
토큰화 작업과 특히 특수 문자는 추후 모델의 성능에 영향을 끼칠 수 있어 제거 시 잘 생각하여야 합니다.
또 영어에서 자주 사용되는 구두점은 여러 경우(단어 자체에 포함되어 있는 것인지, 문법적으로 필요한 표현인지 등)를 고려하여 제거해야 합니다.
숫자나 특수 문자를 제거하는 파이썬 코드는 다음과 같습니다.
정규표현식과 replace를 이용하였고, 정규표현식에 대한 내용은 추후 업데이트 할 예정입니다.
코드 결과는 주석 처리하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import re
sent = '2024.02.14 Happy Birthday !@!'
#정규표현식으로 숫자 제거하기
rm_num_sent1 = re.sub(r"[0-9]", "", sent)
print(rm_num_sent)
#.. Happy Birthday !@!
rm_num_sent2 = re.sub(r'\d+', '', sent) #\d는 숫자 0~9를 의미
print(rm_num_sent2)
#.. Happy Birthday !@!
#정규표현식으로 문자 제거하기
rm_char_sent1 = re.sub(r'[^\w\s]', '', sent) #원래 문장에서 특수기호 제거
print(rm_char_sent1)
#20240214 Happy Birthday
rm_char_sent2 = re.sub(r'[^\w\s]', '', rm_num_sent2) #숫자를 제거한 문장에서 특수기호 제거
print(rm_char_sent2)
# Happy Birthday
#replace로 원하는 문자 제거하기
rm_char_sent3 = sent.replace('@', '')
print(rm_char_sent3)
#2024.02.14 Happy Birthday !!
토큰화
텍스트의 문맥 정보를 담고 있는, 의미를 가지는 단위로 분할하는 과정을 토큰화라 합니다.
영어에서는 보통 구두점(‘.’, ‘.’, ‘?’, ‘;’ 등과 같은 기호)이나 공백(띄어쓰기)을 토큰화 단위로 사용합니다.
토큰을 어떻게 설정할 것인지에 따라 토큰화의 결과가 달라집니다.
 토큰 단위마다 다른 It’s의 토큰화
토큰 단위마다 다른 It’s의 토큰화
BERT 토크나이저를 이용해 문장을 토큰화하는 파이썬 코드는 다음과 같습니다.
토큰화의 방법에 대한 여러 코드는 추후 업데이트 할 예정입니다.
코드 결과는 주석 처리하였습니다.
1
2
3
4
5
6
7
8
from transformers import BertTokenizer
# BERT 토크나이저 불러오기
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
tok = tokenizer.tokenize("Hello, It's good to see you")
print(tok)
#['hello', ',', 'it', "'", 's', 'good', 'to', 'see', 'you']
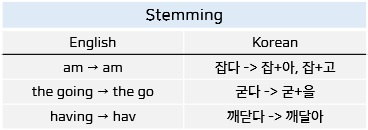
어간 추출
어간은 단어의 의미를 담고 있는 핵심 부분입니다. 이를 추출해 말뭉치의 복잡성을 줄이거나 문서의 단어 수를 줄이는 데 사용합니다.
하지만 추출 과정에서 품사 정보를 보존하지 않기 때문에 토크나이저의 vocabulary(말뭉치 사전)에 없는 단어일 확률이 높아집니다. 그렇기 때문에 어간 추출을 이용해 단어를 분석하기에는 무리가 있습니다.
인텐트 추출
인텐트란 사용자 말의 의도를 나타내며, 컴퓨터가 대화 시나리오를 처리하는 용도로 사용됩니다.
내부의 자연어 이해(NLU) 모듈을 거쳐 인텐트를 추출하며, 시스템은 이 인텐트를 기준으로 대화를 처리합니다.
예를 들면, add playlist, add my list, add song이라는 단어를 통해 ‘add to playlist’라는 인텐트를 파악합니다.
문장이 뜻하는 의미를 알아내기 위해서는 인텐트 분류 모델을 사용해야 합니다.
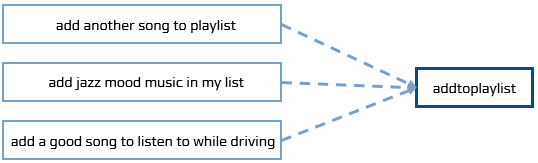 인텐트: 리스트에 노래 추가
인텐트: 리스트에 노래 추가
Comments powered by Disqus.